微调(Fine-Tuning)是在特定任务或领域上进一步训练大型语言模型(LLM)的过程。这可以通过使用预训练的LLM作为起点,然后在特定任务或领域的标记数据集上训练它来完成。微调可以通过调整模型的权重来更好地拟合数据,从而提高LLM在特定任务或领域上的性能。
微调(Fine-tuning)是指在预训练(Pre-training)阶段之后,使用特定任务的有标签数据对模型进行进一步的训练和调整参数,以使其在目标任务上获得更好的性能。
在微调过程中,预训练得到的模型参数作为初始状态,然后在特定任务的有标签数据上进行训练。通常,只有少量的有标签数据可用于微调,这使得模型能够更好地适应目标任务的特定要求。
微调的关键是调整预训练模型的参数,以使其更好地适应目标任务的特定领域或数据分布。这个过程通常包括以下几个步骤:
冻结部分参数:为了保持预训练模型的初始表示能力,通常会冻结部分参数,特别是底层的参数,使其在微调过程中保持不变。这样可以避免较大的参数更新,防止过度调整模型的初始表示。
更新顶层参数:针对目标任务的特定要求,通常会添加一个或多个新的层,这些层称为顶层(top layers)。这些顶层将与预训练模型连接,并根据目标任务的标签数据进行训练。在微调过程中,主要是更新这些顶层参数,以使其适应目标任务的特定输出。
调整参数:在微调过程中,通过反向传播算法和优化方法(如随机梯度下降),根据目标任务的损失函数来调整模型的参数。由于预训练模型已经通过大规模无监督学习进行了初始化,微调过程通常只需要较少的训练数据和较少的迭代次数。
微调的目标是将预训练模型的泛化能力与目标任务的特定要求相结合,从而获得更好的性能。通过使用预训练模型的特征表示和参数初始化,微调可以加快模型在目标任务上的收敛速度,并提供更好的泛化能力。
微调广泛应用于自然语言处理(NLP)、计算机视觉(CV)和其他机器学习领域。例如,在NLP中,预训练模型(如BERT、GPT)可以通过微调在特定的下游任务上获得显著的性能提升。在CV领域,通过微调预训练模型(如ImageNet预训练模型),可以在特定的目标识别、目标检测任务上获得更好的结果。
微调(Fine-tuning)是指在预训练(Pre-training)阶段之后,使用特定任务的有标签数据对模型进行进一步的训练和调整参数,以使其在目标任务上获得更好的性能。
在微调过程中,预训练得到的模型参数作为初始状态,然后在特定任务的有标签数据上进行训练。通常,只有少量的有标签数据可用于微调,这使得模型能够更好地适应目标任务的特定要求。
微调的关键是调整预训练模型的参数,以使其更好地适应目标任务的特定领域或数据分布。这个过程通常包括以下几个步骤:
冻结部分参数:为了保持预训练模型的初始表示能力,通常会冻结部分参数,特别是底层的参数,使其在微调过程中保持不变。这样可以避免较大的参数更新,防止过度调整模型的初始表示。
更新顶层参数:针对目标任务的特定要求,通常会添加一个或多个新的层,这些层称为顶层(top layers)。这些顶层将与预训练模型连接,并根据目标任务的标签数据进行训练。在微调过程中,主要是更新这些顶层参数,以使其适应目标任务的特定输出。
调整参数:在微调过程中,通过反向传播算法和优化方法(如随机梯度下降),根据目标任务的损失函数来调整模型的参数。由于预训练模型已经通过大规模无监督学习进行了初始化,微调过程通常只需要较少的训练数据和较少的迭代次数。
微调的目标是将预训练模型的泛化能力与目标任务的特定要求相结合,从而获得更好的性能。通过使用预训练模型的特征表示和参数初始化,微调可以加快模型在目标任务上的收敛速度,并提供更好的泛化能力。
微调广泛应用于自然语言处理(NLP)、计算机视觉(CV)和其他机器学习领域。例如,在NLP中,预训练模型(如BERT、GPT)可以通过微调在特定的下游任务上获得显著的性能提升。在CV领域,通过微调预训练模型(如ImageNet预训练模型),可以在特定的目标识别、目标检测任务上获得更好的结果。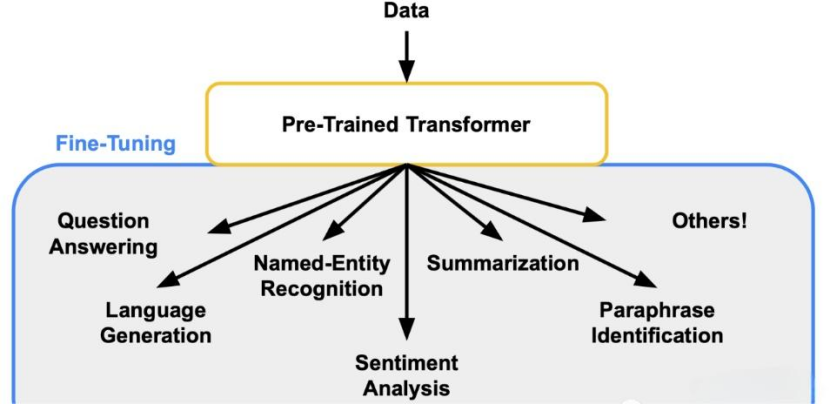
监督微调(Supervised Fine-Tuning):SFT使用标记数据来训练LLM。标记的数据由输入和输出数据对组成。输入数据是LLM将得到的数据,输出数据是LLM期望生成的数据。SFT是一种相对简单和有效的方法来微调LLM。
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback):RLHF使用人类反馈来训练LLM。反馈可以通过多种方式收集,例如调查、访谈或用户研究。RLHF是一种更复杂、更耗时的方法来微调LLM,但它比SFT更有效。
应该使用哪种方法?
微调 LLM 的最佳方法取决于许多因素,例如标记数据的可用性、可用时间和资源以及所需的性能。如果有很多可用的标记数据,SFT 是一个不错的选择。但是如果没有可用的标记数据,或者如果需要将 LLM 的性能提高到 SFT 无法达到的水平,RLHF 是一个不错的选择,但是RLHF 需要更多的事件和后期的人工参与。
微调的好处
微调可以提高 LLM 在特定任务或领域上的性能,可以为自然语言生成、问答和翻译等任务带来更好的结果。微调还可以使 LLM 更具可解释性,这有助于调试和理解模型的行为。
简而言之,Fine-tuning 是语言模型学习过程中的后续步骤。在经过预训练后,模型根据特定于任务的标记数据进行微调,以使其知识适应特定的下游任务。
迁移学习:微调利用迁移学习,其中模型将学习到的表示从预训练转移到目标任务。
特定于任务的数据:模型在特定于目标任务的标记数据上进行训练,例如带有情感标记的句子或问答对。
基于梯度的优化:微调通常涉及基于梯度的优化技术,以根据特定于任务的数据更新模型的参数。
微调使模型能够在各种特定的自然语言处理任务中表现出色,包括情感分析、问题回答、机器翻译和文本生成。像BERT这样的预训练语言模型可以在标有积极或消极情绪的客户评论数据集上进行微调。一般的微调任务如下:
情感分析:微调模型可以用于情感分析任务,例如分析客户评论、社交媒体情感监控和市场研究。
文本分类:微调允许模型将文本分类到预定义的类别中,从而支持主题分类、垃圾邮件检测和文档分类等应用程序。
问答:通过对问答对进行微调,可以使用模型根据给定的上下文回答特定的问题,帮助完成客户支持和信息检索等任务。
总的来说,微调是在预训练之后使用特定任务的有标签数据对模型进行进一步训练和调整参数的过程,以使其在目标任务上获得更好的性能。通过结合预训练模型的表示能力和特定任务的调整,微调可以提高模型的适应能力和泛化能力。