一、什么是attention机制
Attention机制:又称为注意力机制,顾名思义,是一种能让模型对重要信息重点关注并充分学习吸收的技术.通俗的讲就是把注意力集中放在重要的点上,而忽略其他不重要的因素。其中重要程度的判断取决于应用场景,拿个现实生活中的例子,比如1000个人眼中有1000个哈姆雷特。根据应用场景的不同,Attention分为空间注意力和时间注意力,前者用于图像处理,后者用于自然语言处理.
二、为什么需要注意力机制
注意力机制最早用在seq2seq模型上,原始编解码模型的encode过程会生成一个中间向量C,用于保存原序列的语义信息。但是这个向量长度是固定的,当输入原序列的长度比较长时,向量C无法保存全部的语义信息,上下文语义信息受到了限制,这也限制了模型的理解能力。如下图:
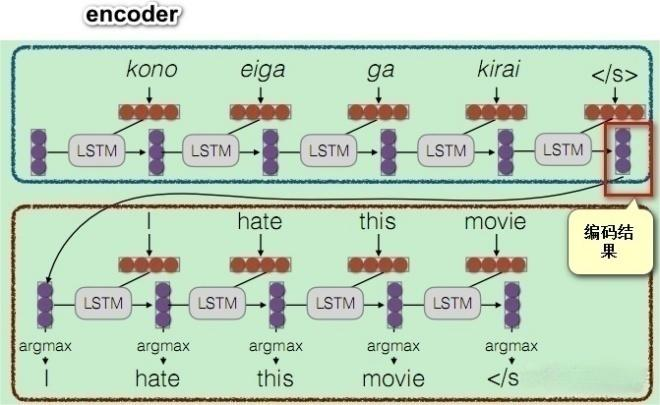
这种编码方法,无法体现对一个句子序列中不同语素的关注程度,在自然语言中,一个句子中的不同部分是有不同含义和重要性的,比如上面的例子中:I hate this movie.如果是做情感分析的应用场景,训练的时候明显应该对hate这个词语做更多的关注。
三、Attention的原理
在transformer中self-attention机制一种是加了masked,一种没有加,其本质结构和算法是一样的。加了mask的attention机制用在decoder中,他根据postional encoding的信息,来确保对位置i的编码输出只能依赖于小于i的输入,这里是有从左到右性质的,与encoder不一样;我们先看attention机制的结构图。如下:
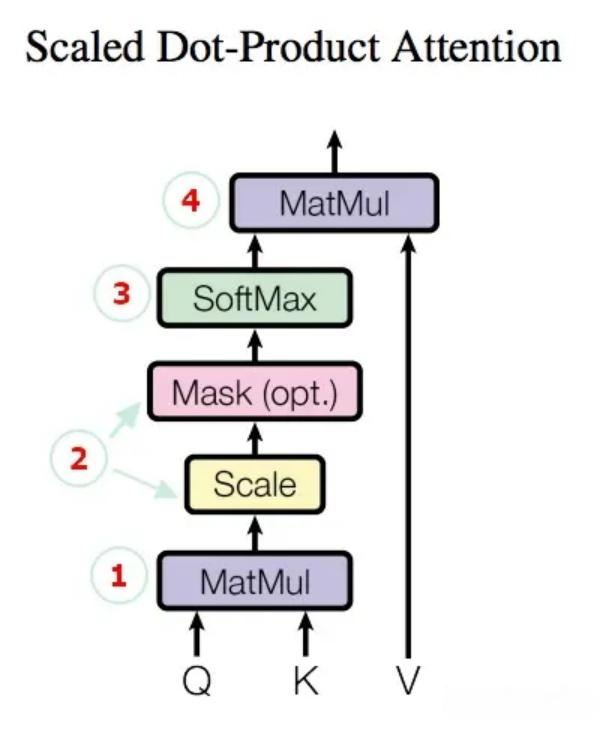
那我们逐一详解来介绍
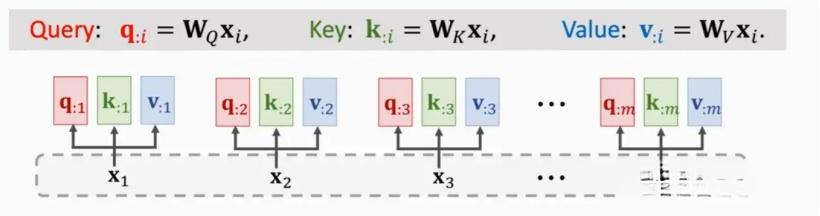
第一步:随机初始化三个全局向量,Wq,Wk,Wv,把输入x变成三个,Q表示数序,K注意力集中的点,V是值,用计算的权重来乘以他的,表示x意义,这个我的理解;然后通过计算Q和K的点积来查看距离相似的语义含义;
第二步和第三步 计算权重:如上文所述,拿每一个qi和所有的k进行点积相乘(可参见上一篇attention的文章),乘之后再除以根号dmodel进行缩放,然后放到一个softmax函数里面,变到(0,1)之间,这个(0,1)的值就是每个位置的注意力权重;如果是在decoder里面,那么就要根据position encoding来把部分数据掩盖掉,具体的做法是把他设置为无穷大,这样在softmax输出后,就变成接近0了。
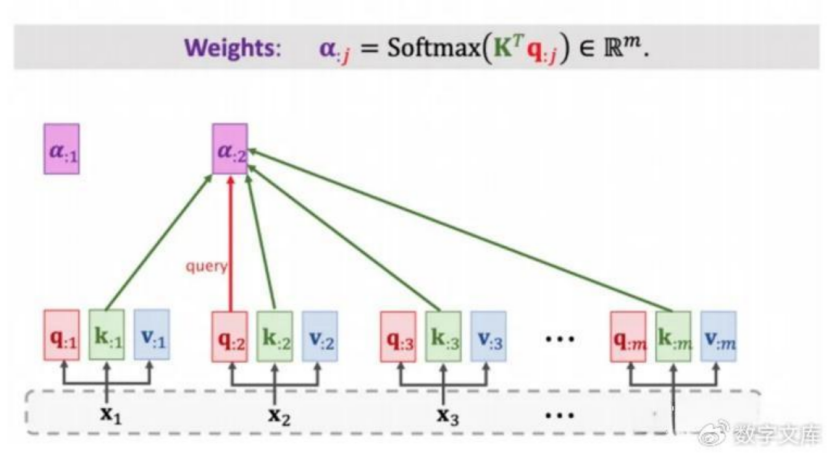
第四步:输出权重。将权重的比例乘以Value的值(输出C),就得到self-attention最终的值了。
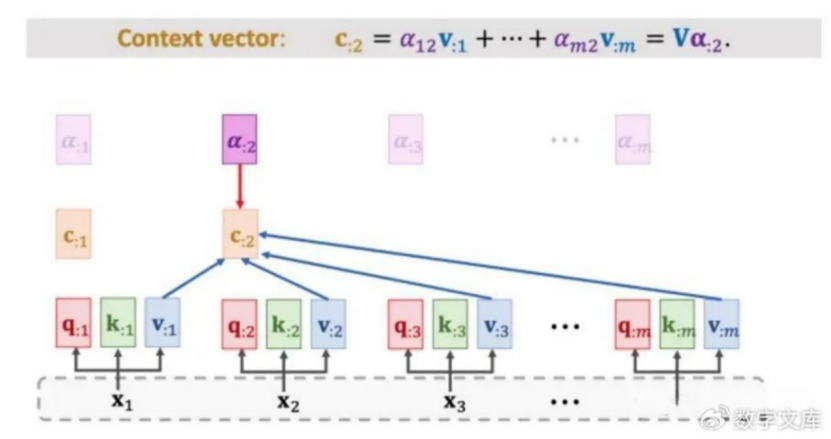
2. attention机制
其做法与self-attention机制一样,只是部分值不一样,注意x的不同。
第一步:注意不一样的地方,K和V是来自于encoder的,而Q是来自于decoder的x’。
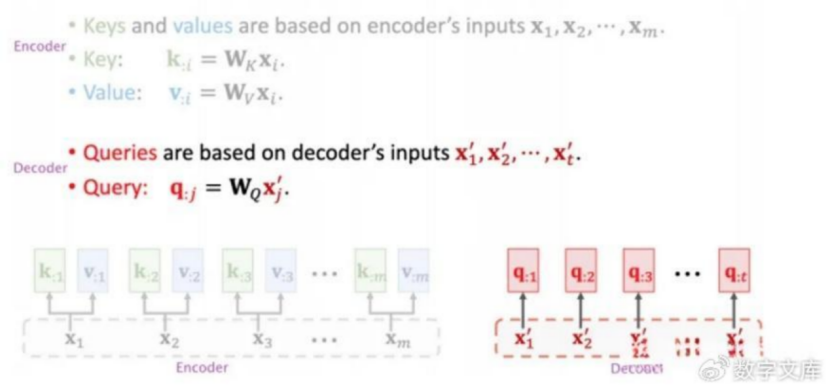
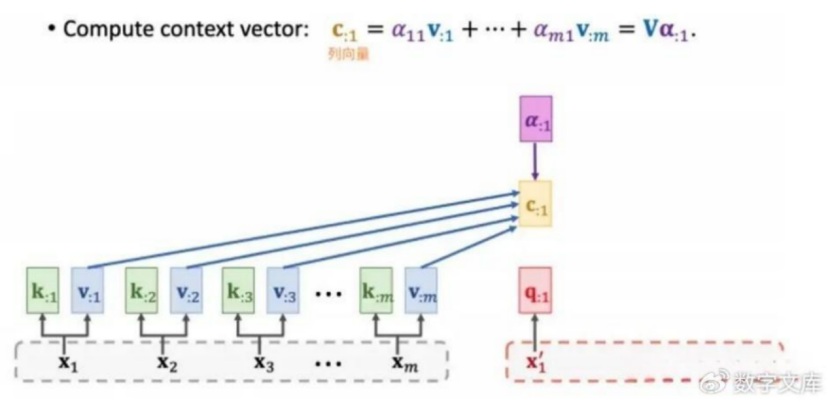
后续的步骤都是一样的,一样计算出权重,一样根据value计算出输出C
3. multi-head机制
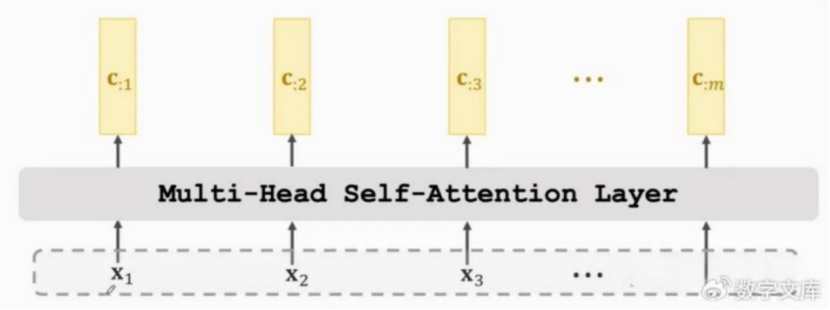
多头的原理跟单头一样,对于self-attention,每个单头的输入都是一样,都是同样的x,但是他们的WQ,WK,WV不共享,各不相同,对于论文中,他们用了8头。把每个单头的输出堆叠起来,也是concat起来,就是多头的输出。
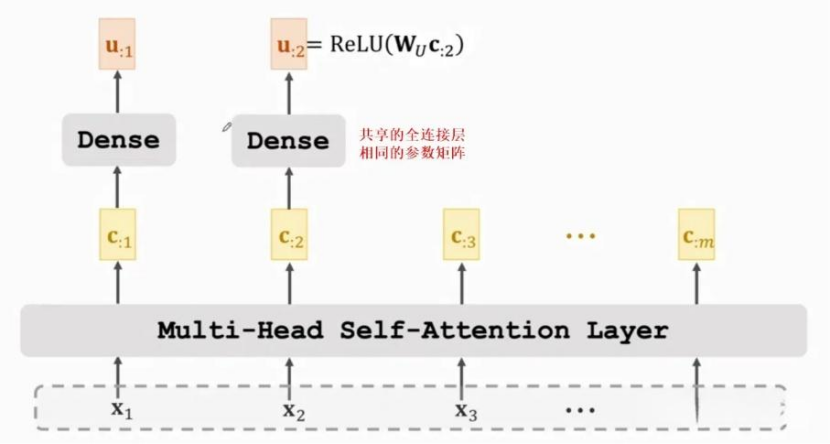
然后再把输出的C放到一个全连接层,然后把输出的结果通过RELU激活函数,得到的结果就是多头attention的输出。
至此,transformer中的各种attention机制介绍完毕。