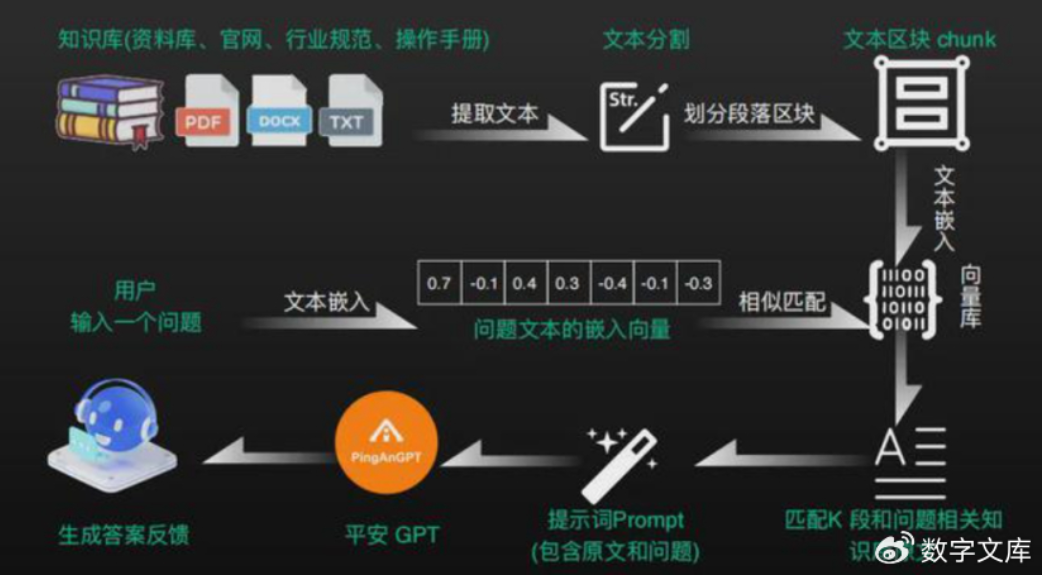
假如您正在面对一座巨大的数据山峰,信息纷繁复杂,难以梳理。此时,Chunking 技术出现了,它如同一位智慧的登山向导,将这座山峰分割成一个个可攀登的小块。这种技术的魅力在于,它能够化繁为简,让复杂的问题变得易于处理。就像在网页加载优化方面,通过 Chunking 技术,可以将大型文件分割成小块进行传输,显著提升用户的访问体验。
分块最佳策略选择:
分块并不是一个简单的问题。行业并没有一种通用的标准。
最佳的分块策略取决于具体的用例。
幸运的是,你不仅仅是简单地对数据进行分块、向量化然后碰运气。
你还有元数据。这可以是指向原始块或更大文档部分的链接、类别和标签、文本,或者实际上任何内容。正如 Schwaber-Cohen 所说:“这有点像一个 JSON blob,你可以用它来过滤东西。如果你只是在寻找特定子集的数据,你可以大大减少搜索空间,并且你可以使用元数据将你在响应中使用的内容链接回原始内容。”
总而言之,大小很重要。而选择最佳的分块策略和利用元数据则可以进一步提高检索和响应的效率和准确性。
分块策略:
一般有以下四种分块策略
1、固定大小块分块策略(fixed sizes)
在处理数据时,一种常见的方法是将文本分成固定大小的块。这种方法适用于内容格式和大小相似的数据集,如新闻文章或博客帖子。虽然这种方法成本较低,但它并未考虑到分块内容的上下文,可能对某些应用场景影响不大,但对于其他场景可能非常重要。
2、随机块分块策略( random chunk sizes)
如果数据集包含多种文档类型,一种可行的方法是使用随机大小的块。这种方法可能捕捉到更广泛的语义上下文和主题,而不受任何给定文档类型的约定的限制。然而,随机块可能导致文本被打断,产生无意义的块。
3、滑动窗口分块策略(sliding windows)
滑动窗口方法是一种常用的分块策略,它使新的块与前一个块的内容重叠,并包含部分内容。这样可以更好地捕捉每个块周围的上下文,提高整个系统的语义相关性。然而,这也需要更多的存储空间,并可能导致冗余信息,使搜索过程变慢,并增加RAG系统提取正确来源的难度。
4、上下文感知分块策略(Context-aware chunking)
上下文感知分块方法根据标点符号或Markdown/HTML标签等语义标记将文本分块。这种方法可以递归地将文档分成更小、重叠的片段,每个片段都能保持上下文的完整性。尽管这种方法可以提供良好的结果,但它需要额外的预处理来分割文本,可能增加了计算需求,从而减慢了分块过程。
确定最佳方法
要确定适合你用例的最佳分块策略,需要一些工作。
测试不同方法的效果,并根据评估结果选择最佳策略。通过人工审核和LLM评估器对它们进行评分。当你确定哪种方法表现更好时,你可以通过基于余弦相似度分数对结果进行进一步过滤来进一步增强结果。分块只是生成式AI技术拼图中的一部分,我们还需要LLM、矢量数据库和存储。最重要的是,要有一个明确的目标,这样才能确保项目取得成功。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。