探索大模型背后奥秘,解读其基本原理,开启智能新时代。
大模型的基本原理:
大模型,也就是我们经常遇见的大语言模型,简称LLM。可以通过三个核心概念来阐述,1:基于GPT的预训练框架、2:Transformer的深度学习架构,3:以及将文本转化为语义向量的映射技术。
1 GPT:
GPT,全称是Generative Pre-trained Transformer,是一个先进的自然语言处理模型,由OpenAI在2018年推出。以下是对GPT每个字母含义的通俗解释:
G,即“Generative”,表示GPT模型具有生成文本的能力。它可以根据输入的文本或提示,生成自然、流畅的文本内容,展现出强大的语言生成能力。
P,即“Pre-trained”,指的是在对模型进行特定任务微调之前,先对其进行大量文本数据集的预训练。这使得GPT模型能够学习到丰富的语言知识和上下文信息,为 后续的特定任务提供更好的基础。
T,即“Transformer”,是GPT模型所用的基本架构。Transformer模型通过自注意力机制,能够识别文本中的语法和上下文,从而生成更自然和流畅的文本。GPT模型基于Transformer架构,通过多层的神经网络结构,实现了对语言的深入理解与生成。
总的来说,GPT模型通过生成式的预训练方式和Transformer架构,展现出了强大的自然语言处理能力,为自然语言处理领域的发展带来了新的突破。无论是在文本生成、语言理解还是对话系统等方面,GPT模型都展现出了广泛的应用前景。
2 Transformer
Transformer,源自2017年Google发布的论文《Attention is All You Need》中提出Transformer架构。若是你想深入了解Transformer架构的原理,建议你精读这篇论文。
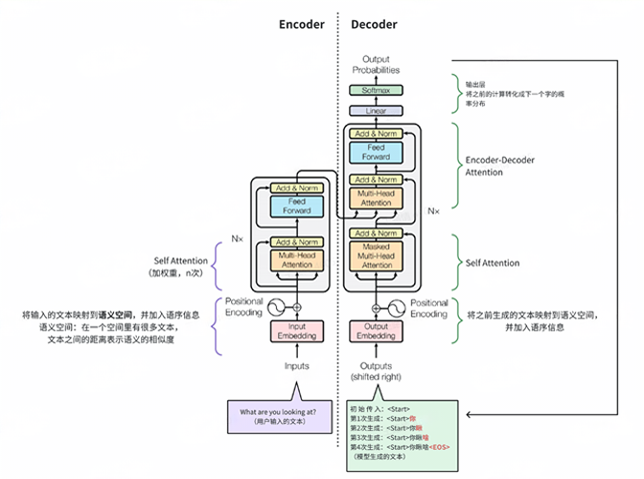
2.1 Tranformer架构主要由两部分组成:编码器(Encoder)和解码器(Decoder)
编码器,用于对输入的文本进行理解,把文本编码到包含词意、语序、权重(词重要度)的语义空间;
解码器,用于生成文本,即将编码器输出的语义空间的内容解码为文本(生成文本)
2.2 Transformer的核心机制:Self-Attention(自注意力机制)
注意力机制,用于找到一句话中重要的字/词,类似人阅读一句话,会判断这句话的重点。注意力机制这个逻辑,可以进一步拓展到多模态(图片、音频和视频)。简而言之,就是展现出一种【找重点】的能力。
自注意力机制,是指一句话通过词的彼此对比来找重点。
多头注意理解机制,找多个重点。类似我们人类看待问题的时候,建议从多个角度看待问题,以更全面地认知和理解。同样,多头注意力机制,也有这种类似,从多个角度找重点。
3 文本映射到语义空间
文本映射到语义空间需要两步处理:
1)Tokenizer(分词器)
2)Embedding(嵌入)
3.1 Tokenizer
GPT使用BPE(Byte Pair Encoding)作为分词器,它的原理是将字、词拆成一个个字节,统计训练中的“字节对”出现的频次,选择出现频次最高的“字符对”,合并为一个新的符号,并基于新的符号再出统计频次再进行一轮新的合并,最大达成目标大小。而这些符合的集合我们称之为词汇表,字符我们称之为token。

说明:token与我们理解的字/词并不一定有逻辑意义上的对应关系,有的时候可能是一个单词,有的时候可能是一个字,也有可能出现1/3或2/3个汉字的情况(因为一个汉字在unicode编码中是占3个字节的)。
3.2 Embedding
Embedding的一种常见实现方式是Word2Vec。
Word2Vec就是将词映射到多维空间里,词跟词之间的距离代表词跟词之间的语义相似度,所以这个多维空间又叫语义空间。
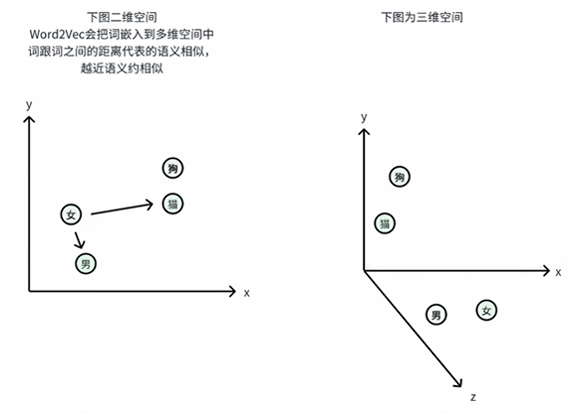
怎么理解多维空间?
同一个词在不同场景下的语义是不同的,比如“King”在性别维度表示男性,在权利维度表示国王。
所以,多维空间j就是描述一个词在不同维度(场景)下的语义。
维度越多表示词的语义越精细,Word2Vec最初的标准是300维,GPT-3为2048维。
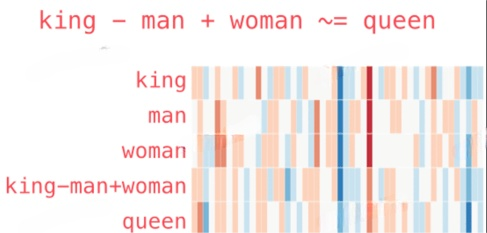
 向量之间的语义是可以计算的。
向量之间的语义是可以计算的。
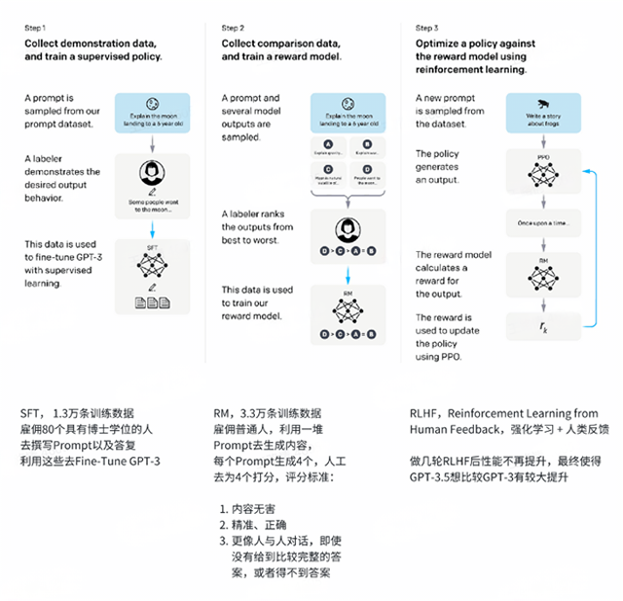
补充:3大模型选型和对比分析
上面3大模型,Bert和T5都是Google提出来,为什么当下OPenAI反而逆袭了Google?
GPT-3.5表现出现跨越式提升,OPenAI做了什么?Fine-Tune。
4、总结
综上所述,大语言模型的基本原理是通过Transformer结构处理文本数据,利用GPT等预训练方法学习语言知识,并将文本映射到语义空间中,以实现复杂的自然语言处理任务。





